The following document describes the way Scaffold groups and thins out the list of proteins shown in the Samples table so the user can focus on the most likely protein identifications present in the experiment. The grouping and paring is achieved using different algorithms depending on whether the Protein Cluster Analysis is selected or not.
- Shared Peptide Grouping and Protein Cluster Analysis
- Clustering Algorithm at Work- an Example
- Displaying Clusters in the Samples Table- an Example
- Legacy Protein Grouping
Shared Peptide Grouping and Protein Cluster Analysis
Scaffold includes the option of applying a method of grouping proteins called Shared Peptide Grouping. Previous versions of Scaffold, prior to version 4, instead used a different grouping algorithm referred to as the Legacy Protein Grouping.
Shared Peptide Grouping is designed to lessen the probability of discarding a valid protein identification when the proteins happens to share peptides with another identified protein. Scaffold also includes the option to assemble proteins into clusters based on shared peptide evidence using Protein Cluster Analysis.
The protein grouping option is selected during file loading by checking Use Protein Cluster Analysis in the Load and Analyze page of Scaffold's Load data Wizard. Choosing this option enables the application of both Shared Peptide Grouping and Protein Cluster Analysis.
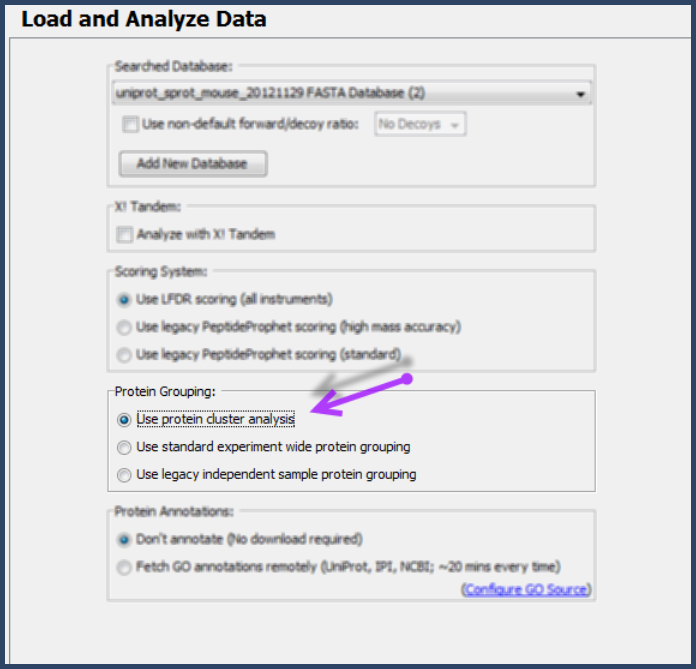
Figure 1. Load and Analyze Window
If during file loading, Protein Cluster Analysis is not selected, it can be reapplied to the already loaded data by going to the Experiment > Edit Experiment... menu. Note, this menu option is only found in a fully licensed version of Scaffold, not in a viewer. Selecting the box for Protein Cluster Analysis and clicking Apply creates clusters using Shared Peptide Grouping and Protein Cluster Analysis.
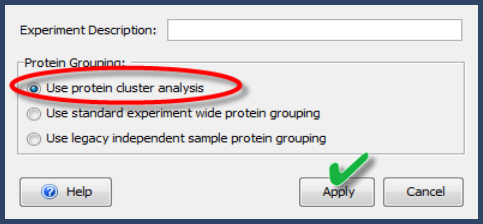
Figure 2. Edit Experiment Window
For explanatory purposes, the grouping and clustering processes can be broken down into the following three phases:
The way shared Peptide Grouping assigns peptides to proteins is quite different from how it is done in the Legacy Peptide Grouping algorithm. Rather than assigning each peptide to a single protein, Shared Peptide Grouping includes a peptide in all of its matching proteins. It then proceeds to form "Protein Groups" and assign weights to each shared peptide, see Weighting Function.
Scaffold considers proteins that share peptide evidence. In cases where two or more proteins share all of their peptides, there is no basis for discrimination among them and the proteins are treated as a unit called a protein group. These proteins appear in the Samples Table as a single line with the accession number of one of them followed by a plus sign and the number of other proteins in the group. The "preferred" or named protein is selected arbitrarily and may be changed by the user.

Figure 3. Samples table, protein grouping
For the purpose of calculating the protein probabilities, shared peptides are apportioned among proteins according the a weighting function. The weights are assigned using the following formula:
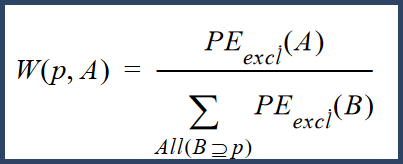
Where W(p,a) is the weight assigned to shared peptide p contained in protein A and in other proteins. PEexcl(A), the exclusive peptide evidence is defined as the sum of the probabilities of each exclusive unique valid peptide X belonging to protein A.
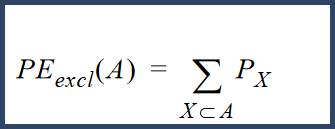
This value is normalized by the sum of the exclusive peptide evidence for each of the proteins that contain peptide p.
Note. A peptide can be set "valid" either manually, by unchecking peptides in the Proteins View Peptide table or globally by using the Experiment menu option Reset Peptide Validation. The Scaffold default cutoff is 0%.
As an example, Figure 4 shows the peptides shared by multiple proteins with their related weights listed in the Similarity view.
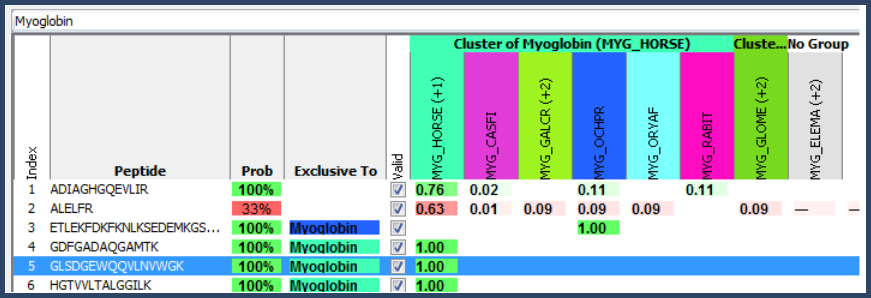
Figure 4. Similarity View- Peptide Weights
These weights are also displayed in the Proteins View Peptide table in the column titled "Apportionments" which replaces the traditional "Assigned" column when the cluster grouping model is used.
Next, the protein list is pared down according to the principle of parsimony. As in the case of the Legacy Protein Grouping, the Shared peptide Grouping algorithm thins down the list of proteins by eliminating any for which there is no independent evidence. However, independent evidence is defined differently in the two grouping algorithms. In the Shared Peptide Grouping a protein is considered having independent evidence when it contains at least one exclusive unique peptide.
Proteins for which there is no exclusive evidence are then eliminated from the protein identification list. This process can best be seen in Scaffold's Similarity View. Here, all proteins sharing peptide evidence are assembled into a table. Proteins with exclusive peptides are placed to the left and included in the experiment. Proteins for which all of the associated peptides are subsumed by these identifications are eliminated from further consideration, as there is no independent evidence of their presence in the experiment. These proteins appear in the "No Group" columns in the Similarity View but are otherwise invisible in Scaffold.
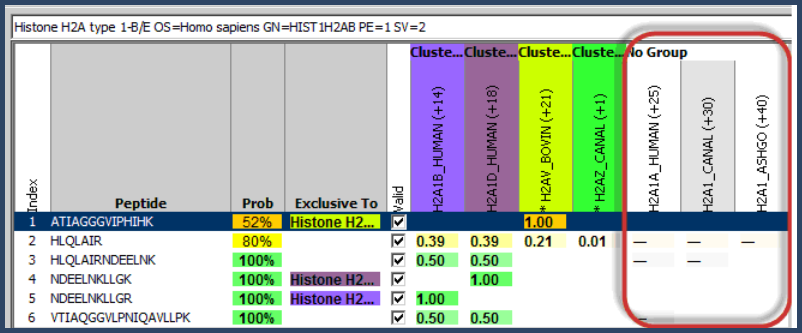
Figure 5. Similarity View- no group columns
Assembling proteins into clusters is based on shared peptide evidence. While akin to Mascot's hierarchical family clustering, Scaffold's Protein Cluster Analysis is more stringent in its requirements for two proteins to appear in the same cluster. This added stringency often succeeds in separating proteins into sets of biologically meaningful isoforms.
In essence, a cluster is a set of proteins with overlapping peptide evidence and may be treated as a proxy for a single identification. This view allows interpretation of identification probability, spectral counts and normalized quantitative values calculated on the level of the clusters.
Cluster formation begins with the creation of protein groups as described above, see Protein Groups. Next, these protein groups are grouped into clusters of similar proteins. Two proteins (or protein groups) are considered similar if their joint unweighted peptide evidence is at least half of the unweighted peptide evidence of either protein. A protein is iteratively added to a cluster if it is similar to at least one other protein in the cluster. This information can be translated into the following rules of thumb for cluster formation.
- For two proteins to be clustered, the sum of the probabilities of their shared peptides must be at least 95%.
- The proteins must share at least 50% of their evidence. This is determined by summing the probabilities of the shared peptides and comparing this value with the summed probabilities of all of the peptides for each individual protein. If the sum of the probabilities of the shared peptides is greater than or equal to half of the sum of the peptide probabilities for either of the individual proteins, a cluster is formed.
- A protein may be included in an existing cluster if it meets the above criteria with a member protein of the cluster.
For a detailed example of how a cluster is formed, see Clustering Algorithm at Work, an Example.
Thresholds and filters do not affect the formation of clusters but they do determine which clusters and proteins or protein groups are displayed in the Samples table. Scaffold builds the Samples table, applying thresholds and filters to the formed clusters, proteins and protein groups in the following order.
- Select all clusters that pass thresholds
- Include all proteins and protein groups belonging to the selected clusters
- Prune proteins or protein groups based on selected filters.
- Remove clusters that do not include proteins
- Prune proteins and protein groups based on thresholds
This order of applying thresholds and filters keeps clusters in the Samples Table that might not include proteins or protein groups that pass thresholds and filters.
Note, filters apply on to proteins or protein groups
Clusters are shown in the Samples View as a line with protein name "Cluster of..." and the name of one of the constituent proteins. This protein is designated as the "primary protein" of the cluster, but the primary protein may be changed by clicking on the accession number field of the cluster and selecting a different accession number from the dropdown list. A cluster may be expanded in the Samples View by clicking on the "+" at the left of the clusters row. When a cluster expands, it displays all of its constituent proteins or protein groups, including the primary protein. The right click menu provides bulk operations to expand or collapse all clusters simultaneously.
The menu option View > Show Entire Protein Clusters will show in a gray font proteins or protein groups in clusters that do not pass thresholds.
Cluster Display Values
Display values are calculated for a cluster as a whole based on the set of peptides that make up the cluster. Note that these values are different from the values of any individual protein, including the primary protein of the cluster. Selecting a cluster and going to one of the other views displays all of the information for the entire cluster.
Figure 6 illustrates Scaffold's method of spectrum and peptide counting in clustered proteins. The circles A, B and C represent three proteins of which B and C form a cluster. The little squares in the circles represent the spectra included in the proteins. Their charge is also indicated. The table on the side shows how the different quantitative values are counted for each protein and for the cluster. Note that the total spectra of the cluster does not correspond to the sum of the total spectra of the protein included in the cluster because some of the peptides are shared.
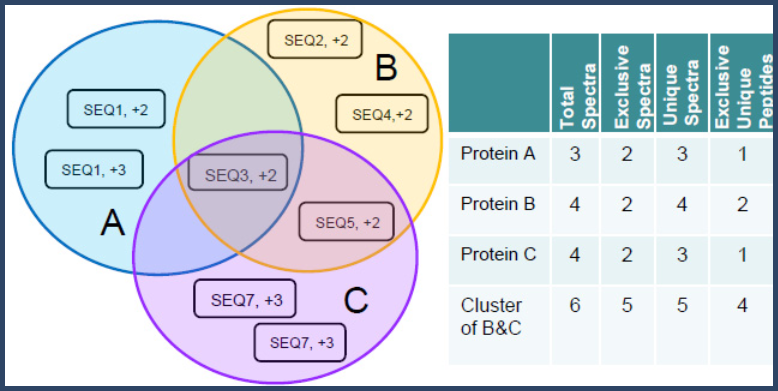
Figure 6. Spectral counting in clustered proteins.
Clustering algorithm at work- an example
To better understand how the clustering algorithm works in Scaffold, we will now go through an example using a protein cluster present in the protein list of the demo file Label-free.sf3.
Note. To open the demo file launch a copy of Scaffold and select Open demo file or if Scaffold is already running, go to the menu Help > Open demo file. From the list of demo files files pick the Label-free.sf3 and click Open From the list of proteins in the Samples table select cluster K1C16_HUMAN[3] Go to the Similarity View by clicking the Similarity View button
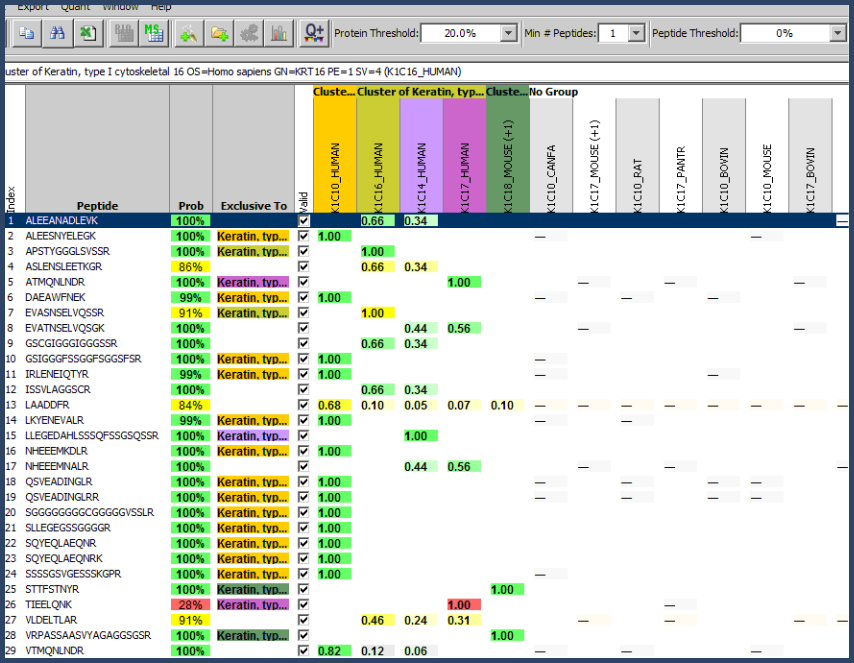
Figure 7. Similarity View- Cluster K1C16_HUMAN[3] from the demo file Label-Free.sf3
The Similarity View shown in figure 7 shows a set of proteins that share peptide identifications. These proteins have already been grouped, and the proteins listed under the "No Group" heading have been eliminated by the principle of parsimony. The remaining protein groups are then candidates for clustering.
Note, clustering considers all "valid" peptides in the remaining protein groups and does not depend on threshold or filter settings.
Step 1. Scaffold computes the sums of the unweighted peptide probabilities for each of the proteins as shown in the following example.
| Peptide | Probability | Weighted Probability |
| ALEANADLEVK | 100% | 0.66 |
| APSTYGGGLSVSSR | 100% | 1 |
| ASLENSLEETKGR | 86% | 0.66 |
| EVASNSELVQSSR | 91% | 1 |
| GSCGIGGGIGGSSR | 100% | 0.66 |
| ISSVLAGGSCR | 100% | 0.66 |
| LAADDFR | 84% | 0.1 |
| VLDELTLAR | 91% | 0.46 |
| VTMQNLNDR | 100% | 0.12 |
| Total | 852% |
Table 1. Sum of unweighted peptide probabilities for protein K1C16_HUMAN
The same process is repeated for the other proteins included in the Similarity View that are not defined as "No Groups"
| Protein | Summed Peptide Probabilities |
| K1C10_HUMAN | 1481% |
| K1C14_HUMAN | 1061% |
| K1C17_HUMAN | 503% |
| K1C18_MOUSE(+1) | 375% |
Step 2. Scaffold calculates the sum of the shared peptide probabilities between the two proteins as shown in Table 2. For K1C10_HUMAN and K1C16_HUMAN, the sum of probabilities of shared peptides is 184%. This is the sum of their two shared peptides, LAADDFR (84%) and VTMQNLNDR (100%).
| K1C10_HUMAN | K1C16_HUMAN | K1C14_HUMAN | K1C17_HUMAN | |
| K1C16_HUMAN | 184% | |||
| K1C14_HUMAN | 184% | 661% | ||
| K1C17_HUMAN | 84% | 175% | 375% | |
| K1C18_MOUSE(+1) | 84% | 84% | 84% | 84% |
Table 2. Shared peptide probabilities
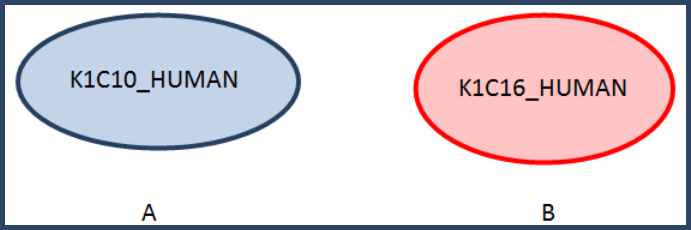
Step 3. The clustering algorithm then proceeds by choosing a protein pair and considering it for clustering:
Test K1C10_HUMAN and K1C16_HUMAN:
Apply the clustering criteria:
- 184% >= 95%
- 184% / 1481% = 10.3%, 184% / 852% = 21.6% so the ratio is lass than 50% for each protein and the proteins are not clustered.
This leads to the formation of two separate clusters:
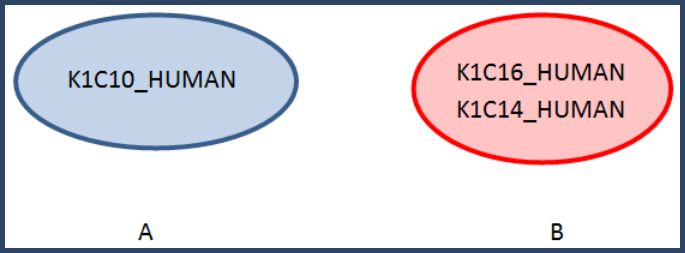
Step 4. The clustering algorithm then tests the next protein for inclusion in each of the established clusters.
Test K1C14_HUMAN:
For Cluster A:
K1C14_HUMAN, K1C10_HUMAN
1) 184% > 95%
2) 184% / 1481% = 12.42, 184% / 1061% = 17.34%, <50%, so no cluster.
For Cluster B
K1C14_HUMAN, K1C16_HUMAN
1) 661% > 95%
2) 661% / 852% = 77.58 > 50%, cluster
Now these are the updated clusters:
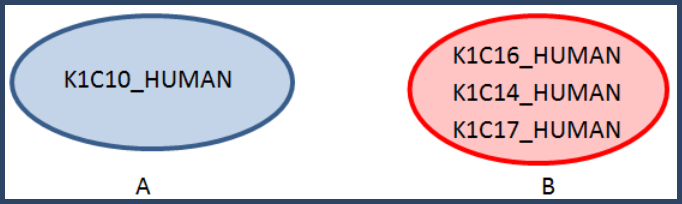
Test K1C17_HUMAN for inclusion in each cluster.
For Cluster A:
K1C17_HUMAN, K1C10_HUMAN
1) 84% < 95%, no cluster
For Cluster B
K1C17_HUMAN, K1C16_HUMAN
1) 175% > 95%
2) 175% / 852% = 20.54%, 175% / 503% = 34.79%, <50%, no cluster
K1C17_HUMAN, K1C14_HUMAN
1) 375% > 95%
2) 375% / 1061% = 35.34%, 375% / 503% = 74.55%, one is >50%, so cluster.
Note, if a protein clusters with one member of a cluster, it joins the cluster
So now we have:
Test K1C18_MOUSE(+1) for inclusion in each cluster
For cluster A:
K1C18_MOUSE(+1), K1C10_HUMAN
1) 84% < 95%, no cluster
K1C18_MOUSE(+1), K1C16_HUMAN
1) 84% < 95%, no cluster
K1C18_MOUSE(+1), K1C14_HUMAN
1) 84% < 95%, no cluster
K1C18_MOUSE(+1), K1C17_HUMAN
1) 84% < 95%, no cluster
So finally we have three clusters

In the Samples View, the single-protein clusters will be designated with the protein name, and the multiple protein clusters will have a summary line for the cluster as well as the individual protein entries.

Figure 8. Samples View- clusters
Displaying Clusters in the Samples Table- an example
Clusters are formed before Scaffold applies thresholds and filters to them and to the protein and groups of proteins they include. The following example example shows how Scaffold goes about in selecting clusters and proteins or protein groups that appear in the Samples Table.
Let's consider for clusters 1,2,3 and 4 with the proteins they include represented by the letters as shown in Figure 9.
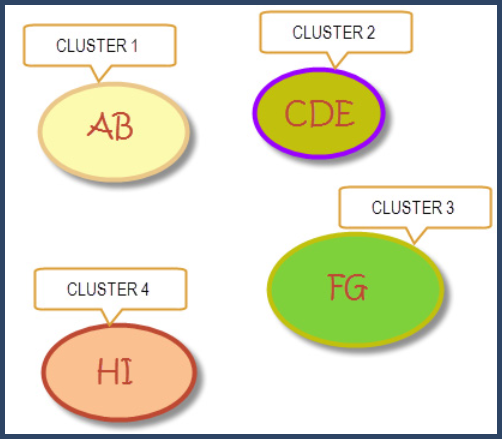
Figure 9. Graphical representation of clusters with their proteins
For a selected combination of thresholds and filters, let's consider the clusters and proteins or protein groups that pass them. Figure 10 summarizes the status for each of the clusters, proteins or protein groups included in this example in respect to the selected thresholds and filters before any of them are applied. A green check is assigned to those clusters, proteins or protein groups that pass thresholds, as well as to those proteins or protein groups that pass filters. Remember that filters are uniquely applied to proteins or protein groups, they do not affect clusters.
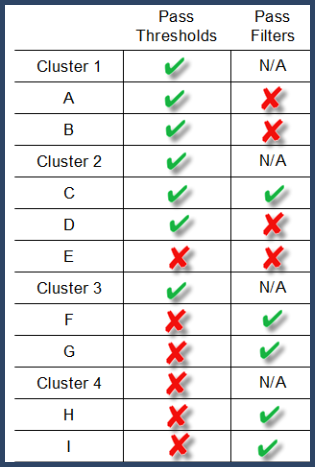
Figure 10. Characteristics of clusters and proteins towards thresholds and filters
Now to establish which cluster, protein or protein group is displayed in the Samples table we create a display list that depends on the status of the clusters and proteins considered, shown in Figure 10 for this example, and the order of their application as described in Clusters in the Samples Table.
Step 1. Select all clusters that pass thresholds
Step 2. Include all proteins and protein groups belonging to the selected clusters
These two selections lead to the initial Display Table as shown in in Figure 11. Note that cluster 4 is not included in the display list since it does not pass the thresholds.
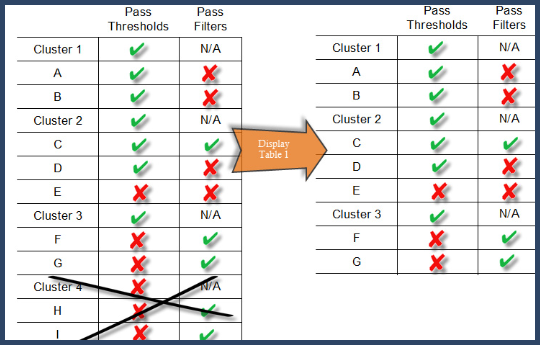
Figure 11. Display Table 1
Step 3. Prune proteins or protein groups based on selected filters.
Now the filters are applied to the proteins and the protein groups for all the clusters and those that do not pass thresholds are eliminated.
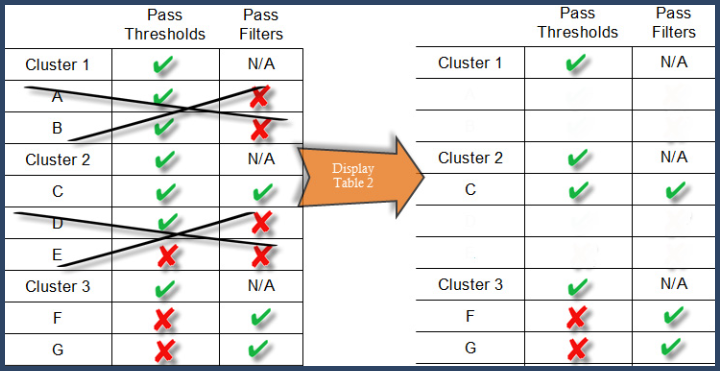
Figure 12. Display Table 2
Step 4. Remove clusters that do not include proteins.
In our example we have cluster 1 that, at this point, does not contain any proteins. Thus cluster 1 is removed from the display table. See figure 13.
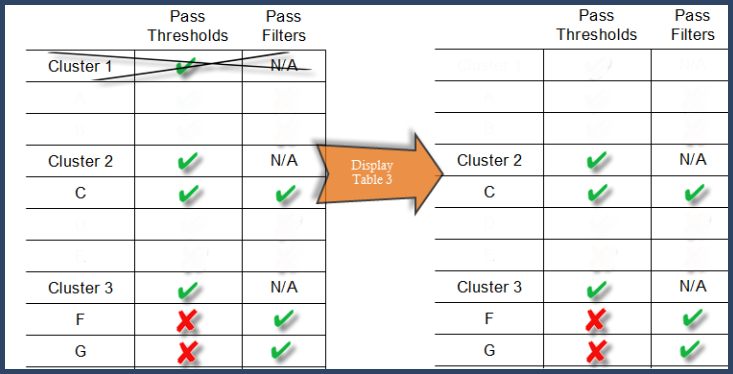
Figure 13. Display Table 3
Step 5. Prune proteins and protein groups based on thresholds
As the last step, thresholds are applied to the proteins and protein groups included in the leftover clusters. In our particular example only two clusters are going to be displayed in the Samples Table: cluster 2 and cluster 3. Of the two, cluster 3 will not include any proteins since they do not pass the thresholds. See figure 14.
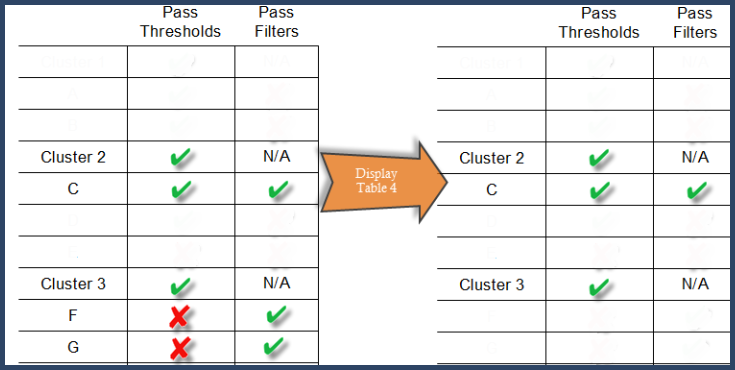
Figure 14. List of clusters and proteins displayed in the Samples Table
To display proteins that are included in the clusters but do not pass thresholds, select the menu option View > Show Entire Protein Clusters, see figure 15. Proteins that do not pass thresholds will be shown written in a dark gray font.
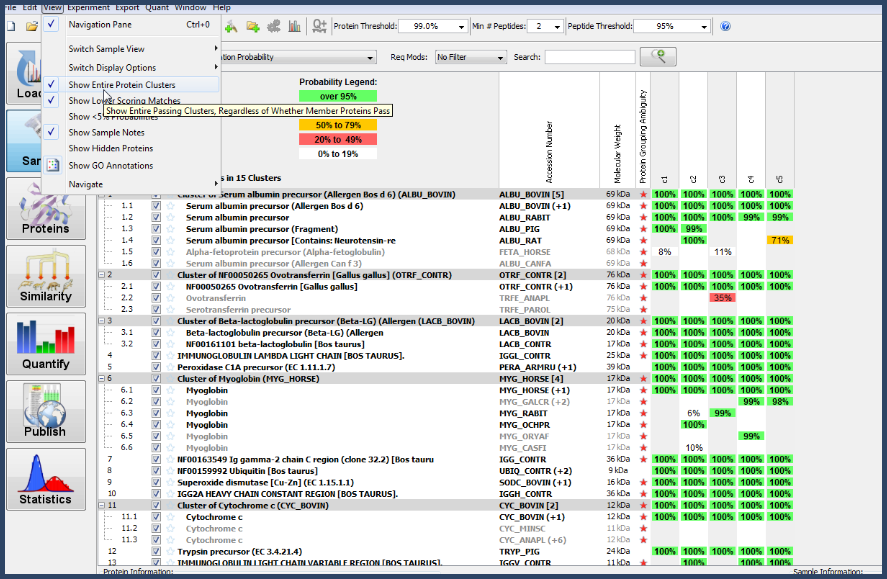
Figure 15. View > Show Entire Protein Clusters.
Scaffold groups proteins with the Legacy Protein Grouping algorithm used in its versions 3 and older when, during the loading phase, the clustering option is not selected or when data is already loaded in Scaffold and the option Use Protein Cluster Analysis is not selected in Edit Experiment menu option.
Generally, the Legacy Protein grouping algorithm groups proteins using a table very similar to the one shown in the similarity view when the Protein Cluster Analysis option is not selected, see figure 16.
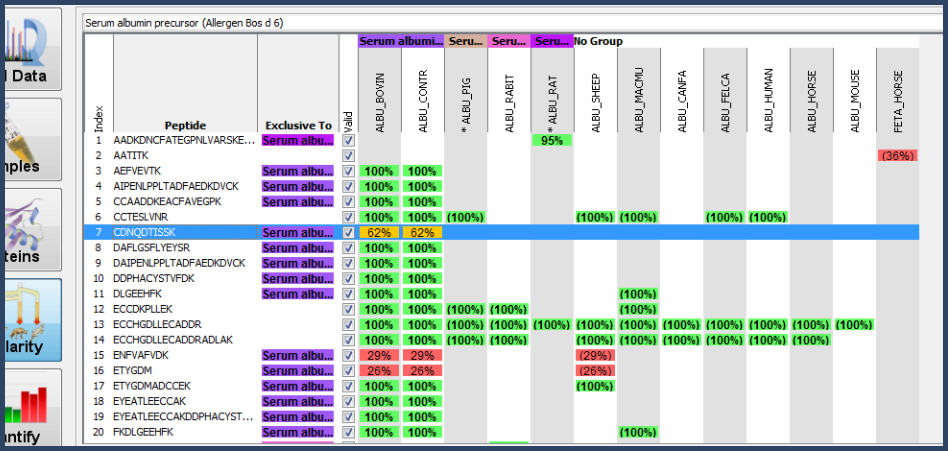
Figure 16. Scaffold Legacy Similarity View
Assigning Peptides to Proteins
Initially the table of peptides and proteins has a column for every protein to which a peptide could potentially be assigned, and a row for every valid peptide that can be found in the listed proteins. When a peptide is found in a protein the peptide probability is shown in the appropriate cell. The sum of the probabilities is then calculated for each protein, see Figure 17.
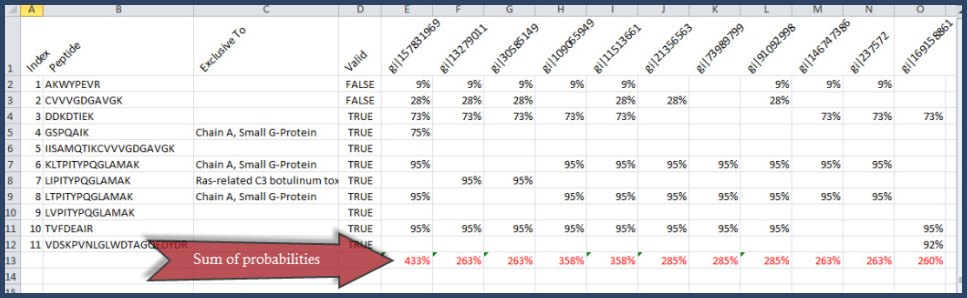
Figure 17. Initial Similarity Table
Each peptide is then assigned to the protein that has the highest total probability among all those where the peptide is found, see Figure 18. If two or more proteins have equal total probabilities and that is the highest for that peptide, it is assigned to all of them.
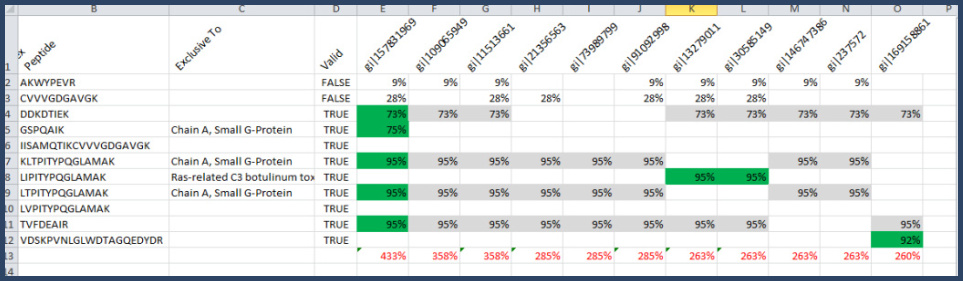
Figure 18. Assigned peptides are shown in green, unassigned in gray
Defining Protein Groups
Now the grouping begins. Proteins with no peptides assigned are eliminated from consideration, the evidence for those proteins has already be accounted for in proteins which are more likely to be present in the analyzed sample. Proteins with the same peptides assigned to them are combined into a group, see Figure 19.
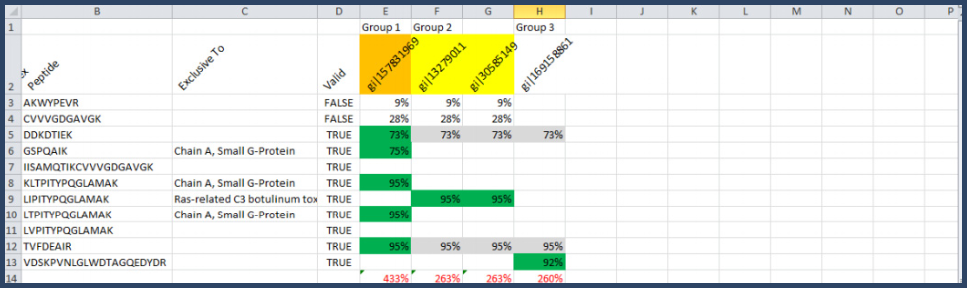
Figure 19. Protein group formation
There is one further complication, however. If the only evidence for a group is a single protein with a probability less than 95%, Scaffold disregards this group. This is based on a heuristic rule built into the algorithm which cuts down on the number of false protein matches displayed. In this case it would eliminate group 3, see Figure 20.
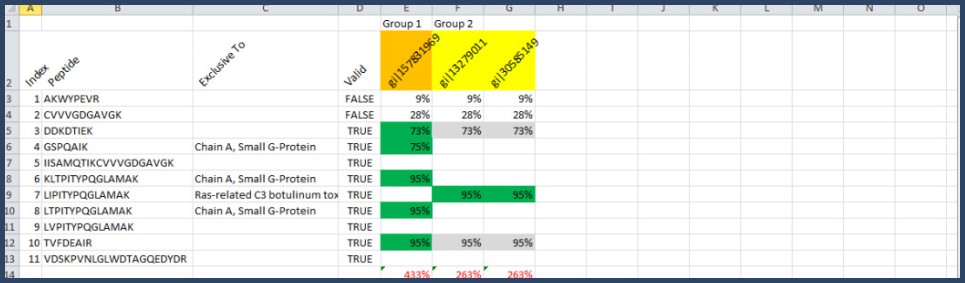
Figure 20. Formed protein groups
Generally, this approach works well to eliminate false assignments, however, in certain instances, it can result in a protein that may actually be found in the sample being eliminated for consideration and thus is not seen in Scaffold's other views. Unfortunately, changing the filter settings has no effect upon this type of grouping algorithm. A different approach can now be tried by using the protein clustering option. The new grouping algorithm does not forcefully assign peptides uniquely to a protein but considers shared peptides among different proteins.